NB: Abstracts below are ordered by section (Keynotes, Papers in panels) and then alphabetical by first author last name
Keynotes
Revisiting Appraisal/Evaluation/Stance: Corpus and Discourse Perspectives
Monika Bednarek (University of Sydney)
25 November 2020, 09:30 on Zoom
Abstract
This paper revisits the linguistic analysis of appraisal/evaluation/stance from both corpus and discourse perspectives. I will draw on research projects across a variety of contexts to identify some of the questions and issues raised in these projects. The main focus of the talk will be on linking analysis of appraisal/evaluation/stance to important methodological concerns and principles in corpus and discourse analysis. Issues discussed may include:
- the selection of texts for analysis;
- the analysis of different modes (intra- vs intersemiotic analysis) and patterns (intra- vs intertextual analysis);
- the direction of analysis (bottom-up vs top-down) and the ‘delicacy’-level of analysis;
- the semiotic resources included under ‘appraisal/evaluation/stance’;
- the transparency and consistency of the analysis;
- the methods/techniques used for the analysis.
I approach this topic from the perspective of my own background as an empirically-oriented corpus-based discourse analyst. The talk will also introduce a new topology for corpus and discourse analysis that researchers can use to increase researcher reflexivity and transparency in the analysis of appraisal/evaluation/stance (and beyond).
Bionote
Monika Bednarek is Associate Professor in Linguistics at the University of Sydney, Australia. She has published widely on evaluation and emotion, including the books Evaluation in Media Discourse (2006) and Emotion Talk Across Corpora (2008) and the special issue of Functions of Language 15/1 on ‘Evaluation and Text Types’. She has also examined the concept of values in the professional context of news discourse, for examine in her co-authored book The Discourse of News Values (with Helen Caple, 2017). Most recently, she has focussed on the analysis of swear/taboo words, including in an article in Discourse, Context & Media 29 (2019) and in a dedicated chapter in Emotion in Discourse (Eds J. Lachlan Mackenzie & Laura Alba-Juez, 2019). She is director of the Sydney Corpus Lab (www.sydneycorpuslab.com) and tweets @corpusling.
Embodied Reading and Imagination
Sarah Bro Trasmundi (University of Southern Denmark)
24 November 2020, 11:30 on Zoom
Abstract
We have scarce knowledge about the reading mechanisms that goes beyond the functional and simple view of reading such as rule-following and problem-solving behaviour; for instance the task of making letter-sound correspondences. Rather than posit reading in a rather abstract, mechanical way – as if all reading were a similar, silent and inward act of mental interpretation – I trace reading to whole-bodied, tactile and active-affective engagement with a material artefact. Further, the materiality of both digital and analogue texts as well as the ability to manipulate the text and the setting during reading is crucial for the reading experience and quality: how we use hands to fetch the text, fingers to turn the pages or touch the keyboard, the voice to bring forth aesthetic and rhythmic flow and, as we experience the results, we write notes, imagine sounds, use gestural and visible expression and give structure to information. In this talk, I therefore discuss some of the prerequisites of experiential reading: To what degree are they a matter of genre and format (scientific texts; poetry), medium (laptop; iPad; print book), purpose (task-based; creative; informational), environment (materials available such as pencils, rulers, music as well as the actual location for reading) etc.? Such investigations provide an understanding of the embodied mechanisms involved in reading which, in turn, impact how we can scaffold (digital) reading practices, so their material engagement supports particular reading purposes and opens up a reader’s imagination. I use cognitive video-ethnography to trace reading to how fine multi-scalar coordination enables readers to engage with written artifacts such as books. An ethnography of reading provides descriptions of how readers use sensorimotor activity to integrate understanding with saccading and actual or imagined vocalization in ways that show how reading connects sensorimotor schemata with highly skilled use of written artifacts (Trasmundi & Cowley, 2020).
References
Trasmundi, S.B. & Cowley, S. (2020). Reading: How readers beget imagining. Special issue: Enaction and Ecological Psychology: Convergences and Complementarities in: Frontiers in Psychology. doi: 10.3389/fpsyg.2020.531682.
Bionote
Sarah Bro Trasmundi works in the intersection between embodied cognition and distributed language. She is particularly interested in the dialogicality of human experience and imagination in various fields such education and clinical healthcare. She is director of the research centre Centre for Human Interactivity (CHI) and the newly established Advanced Cognitive Ethnography Lab (ACE Lab).
Taking Stock: Understanding Readerly Practices under Lockdown
Bronwen Thomas (Bournemouth University)
23 November 2020, 11:30 on Zoom
Abstract
Research on digital reading practices has been facilitated by the fact that online spaces ‘bring into visibility an entirely new social dimension to reading’ (Pinder 2012). The long months of lockdown experienced across the globe in 2020 have made many readers dependent as never before on this social dimension as they seek out new book recommendations, ways of sharing their reading experiences or simply distraction from isolation and fear. But it remains to be seen whether or not the pandemic has given rise to anything new or has changed practices in any significant way, despite all the rhetoric about unprecedented times or the emergence of a ‘new normal’.
In the UK, reading organisations have been quick to try to capture the effects of lockdown on reading, with multiple surveys appearing in the first few weeks inviting readers to document changes to their behaviour and practices. But this desire to take stock was also visible very early on in terms of readers’ own attempts to both examine their own preferences and practices, and to monitor those of others. Here anxiety about the pandemic met with anxieties about productivity and self-worth which have perhaps always been bound up with reading, but particularly so in an age where all of our choices, preferences and behaviours can be so easily quantified.
The stocktaking has revealed some shifts in tastes and practices, for example readers reporting taking up new genres, or reading more on digital devices. Less visible, but no less significant, were the testimonies of readers who struggled to concentrate as well as those for whom the disruption to their daily routines (commuting to and from work, homeschooling) also disrupted their reading. But even this not-reading was something to voice and share, to quantify and externalise so that it could be understood or at least noted.
In this paper I will argue that the opportunities for both readers and researchers to take stock of current and emerging practices under these extreme circumstances can provide insights into the old as well as the ‘new normal’, enabling us to engage with diverse and neglected reading practices and experiences as well as mapping recognisable patterns and trends. Through the analysis of specific examples of taking stock, I will consider what might lie behind this desire, especially in the context of the extreme circumstances in which we find ourselves.
Bionote
Bronwen Thomas is Professor of English and New Media and Head of the Narrative, Culture and Community Research Centre at Bournemouth University in the UK. She has published extensively on fan cultures and online literary communities. Her most recent book, Literature and Social Media, takes a 360 degree approach examining how social media provides unique and distinctive forms of creative expression whilst also facilitating ongoing collaborative discourse amongst both informal and formal networks. She has led four UK government funded projects on digital reading, the latest of which examines issues of accessibility and inclusivity in developing nations (www.drivenetkenya.com).
Papers in Panels
Digitalization and Law – Effects of Novel Reading and Writing Processes on the Legal Discourse
Andreas Abegg & Bojan Peric (ZHAW Zurich University of Applied Sciences / University of Lucerne)
24 November 2020, 10:30 on Zoom
Abstract
The existence of interconnected online texts influences reading and writing – not only of laypeople, but also of professionals dealing with reading, interpretation and writing on a daily basis. In view of the increasing digitalization of legally relevant documents, lawyers in particular are confronted with new reading and writing processes and thus with changes in their own work.
Although these changes are profound, they are indeed difficult to prove. One way to make them visible is digital discourse analysis. Starting with the hypothesis that traces of characteristic discourse dynamics are to be found on the surface of the texts, this method must distance itself from a purely pragmatic approach focusing on meaningful linguistic units only. In the legal discourse, which is primarily based on written text, linguistic elements as well as text characteristics “at the edge of language” can lead to relevant insights.
Analyses of the latter are rare and can most often be found as the by-products of semantically oriented studies. For example, Bubenhofer and Scharloth (2011) examine formal properties of their corpus such as sentence length, text complexity, the amount of passive voice etc. Moreover, Bubenhofer (in print) relates linguistic clusters in online birth reports to their relative position in the text in order to make statements about their narrative structure.
In the legal context, however, other aspects become relevant, i.e. the change of certain text type characteristics on the one hand and the intertextuality of the discourse on the other. Based on a corpus of legal texts spanning more than 150 years, the project “Digitalization and Swiss Law” analyzes text type characteristics such as text length, abstractness or sentence structure as well as implicit and explicit intertextuality (i.e. direct quotations and references and the use of standardized text building blocks) over time. The project’s first results show how changes in the cultural practices of text reading and text production not only modify the writing style, but also the function of courts. Because of certain reading and writing practices, courts are increasingly taking over the role of legislators, a practice they are not entitled to.
References
Bubenhofer, Noah / Scharloth, Joachim. (2011). Korpuspragmatische Analysen alpinistischer Literatur.
Travaux neuchâtelois de linguistique (TRANEL) 55, 241-259.
Bubenhofer, Noah. (in print). Semantische Äquivalenz in Geburtserzählungen: Anwendung von Word
Embeddings. Zeitschrift für Germanistische Linguistik.
Reading and Writing in Online Platforms
Niels Bakker & Marianne Hermans (Dutch Reading Foundation & National Library of the Netherlands)
25 November 2020, 15:55 on Zoom
Abstract
In recent decades, the practices of reading and writing have broadened the scope to the World Wide Web. Online platforms that offer a wide range of products and services have been introduced, including e-bookreading via a subscription-based model (Kobo Plus), reading and writing user-generated stories (Wattpad) and sharing reading experiences with others (Goodreads). These platforms are not well represented in existing studies on trends and developments in reading behavior, carried out by the Netherlands Institute for Social Research and the Foundation for Market Research on Book Reading. As an expression of the digital world, it might be expected that the online platforms mainly attract the millenial generation, thus drawing on a potential for reading and writing in the 21st century.
In order te find out, the researchers were interested in existing online platforms for reading and writing, and which products and services they offer.To gain insight in the market for online reading and writing, a qualitative field study was carried out. Besides this, in a quantitative scan study, data were collected about the online behaviors during the year 2018 of a representative sample of 6.594 Dutch citizens, who gave permission for tracking their digital device.
The results reveal three categories of online platforms. Platforms which enable access to e-books (for example the National Library of the Netherlands), platforms which enable social interaction around books (for example Goodreads) and platforms which enable reading and writing activities (for example FanFiction). This last category is used by the least Dutch citizens. At the same time, the users of these platforms are relatively active and participative. Furthermore, the results highlight that women, younger people and lower educated people are overrepresented among the users. This shows a slightly different profile for the online-platform-reader in comparison with both the printbook and e-book-reader, who is generally older and higher educated. The results thus confirm the expectation of the potential of online platforms for reading and writing in the 21 st century.
References
The Foundation for Market Research on Book Reading (2007-2019). Quarterly research on buying, borrowing and reading books.
https://www.kvbboekwerk.nl/consumentenonderzoek/consumentenonderzoek
The Netherlands Institute for Social Research (2018). Lees: Tijd. Lezen in Nederland. https://www.scp.nl/Publicaties/Alle_publicaties/Publicaties_2018/Lees_Tijd
Pragmalinguistic Annotation of Empathy-Related Practices in Blog Commentations – Discursive Hermeneutics and Deep Learning
Michael Bender (Technische Universität Darmstadt)
25 November 2020, 11:30 on Zoom
Abstract
Digital analyses of pragmalinguistic aspects have to deal with the difficulty of including inferences, implicit meaning and contextual knowledge. These factors also play an important between experts and laypeople via blog commentations where social role behaviour is mutually evaluated and controversial perspectives are discussed (cf. Bender/Janich 2020). The challenge here is to develop linguistic indicators and criteria for determining and detecting empathy-related communication components which serve to initiate and support empathy as well as to signal empathy readiness and expectations – i.e. practices such as the verbalization of adopting the perspective of others, associated procedures for ensuring mutual understanding, and metacommunication on empathy-relevant aspects. However, such phenomena cannot be completely captured directly by automated analyses that only access the linguistic surface – which applies to the majority of digital approaches to corpus and/or discourse analysis (cf. Mautner 2015). They have to be annotated manually by experts first – according to pragmalinguistic criteria and including contextual knowledge on the basis of negotiated guidelines (cf. Weisser 2018: 2-4 and 8-12). In order to achieve intersubjectively comprehensible and reproducible results, collaborative annotation is a good choice (cf. Bender/Müller 2020). Annotations externalise and clarify interpretation, thus enabling collaborative, discursive hermeneutics. But this is time consuming and hardly applicable to large corpora, which makes it desirable to achieve automation. The talk discusses quality criteria of pragmalinguistic annotation and argues possibilities and limitations of automation by machine learning techniques such as recommender systems and deep learning frameworks. The interface between genuinely humanistic, hermeneutic methods and algorithmic techniques, which were actually developed for Big Data, is thus the focus of the paper. Empathy in blog commentations serves as an example-topic for the methodological discussion.
References
Bender, M., Janich, N. (2020): Empathie in der Wissenschaftskommunikation. Eine Forschungsskizze. In: Jacob, K., Konerding, K.-P., Liebert, A. (Eds.): Sprache und Empathie. Book Series: Sprache und Wissen (SuW). Berlin, Boston: de Gruyter. p. 425-449. DOI: https://doi.org/10.1515/9783110679618-014
Bender, M., Müller, M. (2020): Heuristische Textpraktiken in den Wissenschaften. Eine kollaborative Annotationsstudie zum akademischen Diskurs. In: Zeitschrift für Germanistische Linguistik (in print, expected issue 2/2020).
Mautner, Gerlinde (2015): Checks and balances: how corpus linguistics can contribute to CDA. In: Wodak, R., Meyer, M. (Eds.): Methods of Critical Discourse Analysis, London, etc. Sage Publications, p. 154-179.
Weisser, M. (2018). How to Do Corpus Pragmatics on Pragmatically Annotated Data. Amsterdam, Philadelphia: John Benjamins.
The Language of Literary Evaluations
Peter Boot (Huygens Institute for the History of the Netherlands)
23 November 2020, 10:30 on Zoom
Abstract
This paper discusses the language that people use to express positive or negative evaluation of the books they read. The evaluation of literature is a subject that has been discussed from many perspectives. Von Heydebrand and Winko (1996) discuss evaluation in terms of norms. Knoop, Wagner, Jacobsen, and Menninghaus (2016) on the contrary used a bottom-up approach when they asked ‘ordinary’ readers for the terms they use to discuss aesthetic dimensions of literature. This paper takes a corpus-based approach and analyses the words in a collection of ca. 200,000 online book reviews.
We use the tools included in the Sketch Engine software for (lexicographical) corpus analysis (Kilgarriff et al., 2014) to analyse the language of evaluation. Sets of keywords (words characteristic of one corpus when contrasted with a reference corpus) are generated to look at differences between positive and negative reviews and between general literature and suspense. For words denoting aspects of literature, such as ‘character’, ‘style’ and ‘plot’, we create ‘word sketches’, automatic summaries of the common usage patterns of words (Kilgarriff & Tugwell, 2001) as an aid to collocation analysis. Word sketch differences contrast the usage of e.g. ‘plot’ in reviews of general literature and suspense. It is also instructive to create word sketches for general evaluative terms (such as ‘beautiful’) to study their collocations. While many of these collocations are not necessarily unexpected, there are also surprising results, such as the role of terms referring to the body in appraising literature (‘gets under your skin’, ’see it in front of your eyes’) or the fact that general literature, more than suspense, seems to be ‘about’ issues. We will also investigate surprising differences in high-frequency words: why does for example ‘he’ occur more in positive reviews and ‘I’ in negative ones?
References
Kilgarriff, A., Baisa, V., Bušta, J., Jakubíček, M., Kovář, V., Michelfeit, J., et al. (2014). The Sketch Engine: ten years on. Lexicography, 1(1), 7-36.
Kilgarriff, A., & Tugwell, D. (2001). Word sketch: Extraction and display of significant collocations for lexicography. from http://citeseerx.ist.psu.edu/viewdoc/downloaddoi=10.1.1.29.2114&rep=rep1&type=pdf
Knoop, C. A., Wagner, V., Jacobsen, T., & Menninghaus, W. (2016). Mapping the aesthetic space of literature “from below”. Poetics, 56, 35-49.
Von Heydebrand, R., & Winko, S. (1996). Einführung in die Wertung von Literatur: Systematik, Geschichte, Legitimation. Paderborn: Schöningh.
Authenticity in Online Restaurant Reviews: A Corpus Driven Approach to Authenticity as an Evaluative Resource.
Dominick Andrew Boyle (University of Basel)
25 November 2020, 12:00 on Zoom
Abstract
How to writers use authenticity as an evaluative category in online restaurant reviews, and how does this correlate with star rating and sentiment? Discourse on food has offered researchers a rich source of data, for example, Jurafsky Chahuneau, Routledge, and Smith (2014) compellingly show how authors use narratives to convey their stance in online restaurant reviews. Making a judgement concerning authenticity is also a resource which can be used in online appraisals, assessments, and evaluations.
O’Connor, Carroll, and Kovacs (2017) compiled scored wordlists based on four abstract types of authenticity (type, craft, moral, and idiosyncratic). They looked at how discourse correlating to these types of authenticity in reviews can indicate consumers’ perception of a restaurant, and found that higher authenticity scores correlate with a higher star rating and willingness to pay, among other factors.
I examine their measure from a perspective grounded in humanities, using a sample of US restaurant reviews from the Yelp Dataset Challenge (Yelp Inc 2019). First, I compare their ‘authenticity analysis’ with more established sentiment analysis techniques based on Warriner, Kuperman and Brysbaert (2013) as well as star rating, asking what authenticity analysis adds. Overall, I find that authenticity terms correlate positively with both of these more established metrics, but that the subtypes proposed by O’Connor et. al. are not always correlated my data.
I also investigate how authenticity is explicitly discussed by examining correlates of authenticity terms in subcorpora created by star rating, sentiment, and authenticity score. Reviewers are mostly concerned about authenticity of place and taste: authenticity is most collocates with demonyms (Mexican, Chinese) and a positive authenticity score appears to correlate with the trigram the food is, whereas a negative score correlates with the food was. It is my hope that this work will show the importance of authenticity as an aspect of evaluation, especially with regards to food.
References
Jurafsky, D., Chahuneau, V., Routledge, B. R., & Smith, N. A. (2014). Narrative framing of consumer sentiment in online restaurant reviews. First Monday, 19(4).
O’Connor, K., Carroll, G. R., & Kovács, B. (2017). Disambiguating authenticity: Interpretations of value and appeal. PloS one, 12(6).
Van Leeuwen, T. (2001). “What is authenticity?” Discourse studies, 3(4), 392-397.
Warriner, A. B., Kuperman, V., and Brysbaert, M. (2013). Norms of valence, arousal, and dominance for 13,915 English lemmas. Behavior Research Methods, 45(4), 1191-1207.
Yelp Inc. (2019). Yelp Dataset (13) [Data file]. Retrieved from https://www.yelp.com/dataset
An APPRAISAL analysis of online readers’ responses to Julian Barnes’s “The Sense of an Ending.”
Amélie Doche (Birmingham City University)
23 November 2020, 14:30 on Zoom
Abstract
Theoretically informed by Bakhtin’s concept of dialogism (1981), this study explores readers’ online responses to Julian Barnes’s The Sense of an Ending (2011) on Amazon.com. Specifically, it first seeks to examine the two-way intersubjective interaction between Barnes’s novel and the Amazon book reviews. Then, it focuses on the linguistic realisation of interpersonal interactions between the book reviews – and, to a greater extent, the reviewers – and the real or imagined addressee within the Amazon online community.
The Engagement resource of APPRAISAL (Martin & White, 2005) within Systemic Functional Linguistics (SFL: Halliday & Matthiessen, 2004) is used at an analytical level and serves a threefold purpose. First, it examines the interdiscursive space between Barnes’ fictional world and its evaluation through a systemic analysis of projections (SFL). Secondly, it allows for a discussion on the intralocutory space negotiated within the reviews – and how one’s reviewer’s style shapes their reviewer’s identity. Lastly, it addresses interlocutory issues arising from the invisible interaction between the reviews and the online community.
Although the review section is presented as a field that is open to a wide range of discourses, there are hidden rules of the game that determine what will be legitimized. This analysis uses insights from Legitimation Code Theory (Maton, 2014) to explore the hypothesis that these rules are structured around one’s ability to adopt a certain style – particularly, to emulate the professional book review genre (Halliday & Hasan, 1989), established by ideal knowers, such as literary critics. Research findings reveal that style is the legitimacy criterion for a review to be endorsed by the online community.
References
Bakthin, M. (1981). The Dialogic Imagination. Four Essays. Austin: London: University of Texas Press.
Halliday, M., & Matthiessen, C. (2004). An introduction to functional grammar. London: New York: Arnold; Oxford University Press.
Halliday, M., & Hasan, R. (1989). Language, context, and text: Aspects of language in a social-semiotic perspective. Oxford: Oxford University Press.
Martin, J., & White, P. (2005). The language of evaluation: Appraisal in English. Basingstoke: New York: Palgrave Macmillan.
Maton, K. (2014). Knowledge and knowers: Towards a realist sociology of education. London: Routledge.
Evaluations of the Quran in Right-Wing Populist Media. Metapragmatic Sequence Analyses with Topic Modeling
Philipp Dreesen & Julia Krasselt (ZHAW Winterthur)
25 November 2020, 16:20 on Zoom
Abstract
Ideological positions in political discourse are manifested in language use and evaluative and hermeneutical practices such as interpreting or explaining. One example are evaluative speech acts of both non-linguistic and linguistic objects. While participants of rational discourse can be assumed to make knowledge-based argumentative evaluations (Habermas 1981) – e.g. in the form of primary texts or commenting secondary texts (Bayard 2008) –, populist discourse is characterized by evaluations not grounded in knowledge. Particularly the
Quran is used to articulate reasons for the fundamental otherness of people or terrorist acts. In the execution of evaluative and hermeneutical practices as well as in the meta-pragmatic discussion of them (Silverstein 1976), language ideological positions (Kroskrity 2006) become manifest, which in turn shape ideas about the ‘Arabic’ and also fake news. For policy making and the scientific study of islamophobia, it is essential to know the textual forms of these evaluations: How and where are Quran references used? What is quoted? Here, we present a topic modeling approach for the analysis of such evaluative speech acts by using data from right-wing populist online-magazines (PI News and Compact). In the Digital Humanities, topic modeling is a standard tool for quantitative analyses. In contrast to typical application scenarios, shorter textual units are chosen to perform topic analyses at sentence and paragraph level. This allows for a sequential analysis of topic “pathways” in texts in order to examine argumentative structures and their interconnection. We show that texts with “Quran”-topics have a very small spectrum of further topics (with a potentially larger range of topics occurring in the overall corpus), referring in particular to descriptions of violent scenarios initiated by Muslims. Quran references are thus used to discredit the scenarios of violence as following an ‘internal Islamic logic’. The Quran is used to articulate reasons for the fundamental otherness of people or terrorist acts in these contexts.
References
Bayard, Pierre (2008): How to talk about books you haven’t read. London: Granta.
Blei, David M. (2012): Probabilistic topic models. In: Communications of the ACM 55, S. 77. Cameron, Deborah (2005): Verbal Hygiene. Routledge.
Habermas, Jürgen (1981): Theorie des kommunikativen Handelns. Band I: Handlungsrationalität und gesellschaftliche Rationalisierung. Frankfurt/Main: Suhrkamp.
Kroskrity, Paul V. (2006): Language ideologies. In: Duranti, Alessandro (Hg.): A Companion to Linguistic Anthropology. Malden, MA [u.a.]: Blackwell. S. 496–517.
Silverstein, Michael (1976): Shifters, linguistic categories and cultural description. In: Basso, Keith H./Selby, Henry A. (Hg.): Meaning in Anthropology. Albuquerque: University of New Mexico Press. S. 11–55.
Tablets Can Disrupt Reading Comprehension of Primary School Students
Laura Gil & Ladislao Salmerón (University of Valencia)
24 November 2020, 15:30 on Zoom
Abstract
Educational institutions across the world are in a race to integrate digital reading devices in the classroom, under the assumption that computers and tablets will help students to improve their motivation and learning. But children who grow up using tablets for entertainment purposes see this device as a playable tool, which makes reasonable to conclude that they would tend to adopt a shallow processing approach when reading on them (Annisette & Lafreniere, 2017). Evidence for the detrimental effect of digital devices on comprehension, as compared to paper, come from a recent meta-analysis by Delgado et al. (2018). The screen-inferiority effect arose specifically when students were given limited time to complete their reading, a pattern that suggest that students struggle to regulate their reading comprehension processes on digital devices. The authors also identified that the number of studies comparing tablets and printed texts are scarce, and that they were mostly conducted with undergraduates. Thus, the impact of tablets on Primary school students’ text comprehension remains an open issue. To fill this gap, we conducted an experiment in which 208 students from Fifth and Sixth grade from three different schools read two expository texts and, subsequently, answer a set of literal and inferential comprehension questions adapted from national assessment tests. We also analyzed the extent to which higher text comprehension skills could minimize the potential comprehension difficulties elicited by tablets. In a between-groups design, we manipulated the medium (tablet or paper) and the reading time (self-paced or time pressure). Results reveal that reading on tablets, as opposed to reading in print, is particularly detrimental for students with low reading comprehension skills when they read under time pressure. We will discuss the results in light of the Shallowing hypothesis, and will discuss future attempts to identify reading interventions to overcome the screen-inferiority effect.
References
Annisette, L. E., & Lafreniere, K. D. (2017). Social media, texting, and personality: A test of the shallowing hypothesis. Personality and Individual Differences, 115, 154-158.
Delgado, P., Vargas, C., Ackerman, R., & Salmerón, L. (2018). Don’t throw away your printed books: A meta-analysis on the effects of reading media on comprehension. Educational Research Review, 25, 23-38.
Immanent Normativity on Digital Cultural Interfaces — Changing Literary Values in the Age of Digital Media<
Matti T. Kangaskoski (University of Helsinki)
24 November 2020, 16:20 on Zoom
Abstract
I propose to discuss how the contemporary logic of digital cultural interfaces influence literary values and values of reading. I look at literary criticism and prize juries’ statements (e.g. the Man Booker Prize), and specifically the use of readability as a value term for literature.
Digital interfaces have increasingly become the dominant window to our cultural world. Streaming services such as Netflix and Spotify, major international platforms for literature such as Amazon Books, news websites and social media are interfaces that organize vast amounts of cultural data into consumable units. However, the metaphorical window of both the screen and the user’s attention is small. Therefore, cultural products must compete for their place within this small window, arranged into lists such as Top 10, Trending Now, Most Popular, New Titles – aimed to capture the user’s attention. Consequently, cultural producers consciously or tacitly negotiate (Gillespie 2014) the form and content of their work in order to increase their possibilities of finding a higher place in the hierarchy of visibility of a given interface. Similarly, expert reviews and everyday readers’ assessments reflect the values born in these negotiations.
In this talk, I focus specifically on how the logic of the interfaces becomes habitual, enabling the interface and its mode of operation to appear as neutral and transparent. This transformation, I argue, produces immanent normativity (cf. Rouvroy and Berns 2013) and thus allows for the creation of value. Success in this system becomes to mean literary success – and readability within the affordances of this system becomes a literary value.
References
Gillespie, Tarleton. 2014. “The Relevance of Algorithms.” Media Technologies. Essays on Communication, Materiality, and Society. Ed. Tarleton Gillespie, Pablo J. Boczkowski, and Kirsten A. Foot. Cambridge, Mass & London: The MIT Press.
Rouvroy, Antoinette and Berns, Thomas. 2013. “Algorithmic Governmentality and Prospects of
Emancipation. Disparateness as a Precondition for Individuation Through Relationships?” La Découverte.“Réseaux” 2013/1 No 177.
“…and even ‘Mummy-in-Law’ Was Very Enthusiastic” – A Corpus Pragmatic Approach to Evaluative Patterns on a Recipe Webpage
Daniel Knuchel & Noah Bubenhofer (Universität Zürich)
24 November 2020, 09:30 on Zoom
Abstract
Validation of the Story World Absorption Scale Through the Use of Online Reader Reviews
Moniek Kuijpers (University of Basel)
24 November 2020, 13:30 on Zoom
Abstract
Empirical research on absorption has increased over the last decades, but the field also suffers from one important lack, being qualitative data on the nature of absorption in daily life. Absorption has mostly been investigated in lab settings, and because it is an experience that is hard to simulate in a lab, we cannot be sure to what extent the data gathered during experiments is related to how people experience absorption in everyday settings.
In this paper we are looking for instances of absorption in online reader reviews on Goodreads to validate the Story World Absorption Scale (SWAS, Kuijpers et al., 2014). The website Goodreads has collected about 90 million book reviews (goodreads.com) full of descriptions of unprompted daily-life absorbing reading experiences.
Through manual annotation with a group of five annotators we found that in its current form the SWAS is unable to capture ‘daily life’ absorption. This is partly why we needed to adapt the language used on the original scale. We also learned that some of the original statements are hard to match to sentences in reader reviews, even after adapting them to simpler language. This might indicate that the original SWAS encompasses experiences that are not actually that common in daily life absorption (i.e., outside of the lab), or that people do not tend to talk about them in their reviews (e.g., T3:“The story world felt close to me”). Also, context might affect what people talk about. Statements such as “I was not distracted during reading” are important in the lab as evidence that absorption took place; however, in reviews people do not tend to talk about their concentration, perhaps because this is a given in real life reading situations.
This paper will present a new conceptual model of story world absorption. We will present the annotation process and describe what we have learnt from this process about the nature of absorption in daily life.
References
Bálint, K., Hakemulder, F., Kuijpers, M. M., Doicaru, M. M., & Tan, E. S. H. (2016). Reconceptualizing foregrounding. Identifying response strategies to deviation in absorbing narratives. Scientific Study of Literature, 6(2), 176–207. doi: 10.1075/ssol.6.2.02bal.
Kuijpers, M. M., Hakemulder, F., Tan, E. S. H., & Doicaru, M. M. (2014). Exploring absorbing reading experiences. Developing and validating a self-report scale to measure story world absorption. Scientific Study of Literature, 4(1), 89–122. doi: 10.1075/ssol.4.1.05kui.
Rebora, S., Boot, P., Pianzola, F., Gasser, B., Herrmann, J. B., Kraxenberger, M., Kuijpers, M. M., Lauer, G., Lendvai, P., Messerli, T. C., & Sorrentino, P. (preprint). Digital humanities and digital social reading. OSF Preprints, doi:10.31219/osf.io/mf4nj.
Ranking of Social Reading Reviews Based on Richness in Story World Absorption
Piroska Lendvai (University of Basel)
24 November 2020, 14:00 on Zoom
Abstract
Based on a set of user-generated reviews that we manually annotated, the detection of reading absorption with NLP approaches was investigated in e.g. Rebora et al. (2018), Lendvai et al. (2019, 2020). We implemented a method to preselect and rank presumably absorption-rich user reviews from a large, unlabeled social review dump, in order to maximize our annotators’ efficiency. From 2.5 million reviews in English, we extracted a document subset filtered by specific criteria (e.g. book title among most-reviewed books in specific literary genres, 5-star rating, review length). We fine-tuned BERT (Devlin et al., 2018) for the absorption detection task on thousands of labeled review sentences, and used the model to predict and score richness in absorption for unlabeled reviews. Ranking was based on review-level aggregated metrics involving a confidence threshold from the top layer in BERT that we validated on an internal benchmark document set. The method is being tested in pilot annotation rounds and has received positive annotator feedback.
Big Data and Naturalized Social Epistemology: a New Frontier for the Digital Humanities
Charles Lassiter (Gonzaga University)
24 November 2020, 16:50 on Zoom
Abstract
Many openly available datasets capture people’s attitudes and beliefs, providing us with important insights about their relationship with socio-cultural conditions. In this paper, I will use two datasets to illustrate this: Yale University’s Climate Change Opinion Survey and the United States Census Annual Community Survey. The data provide information about the U.S. populations at the level of each of the 3,141 U.S. counties: a political subunit within a state, with a median land area of 600 square miles and a median population of 26,000. While we aren’t able to state with certainty what individuals think, we can identify the socio-epistemic contours of the US by county. Analysis of the data highlights some interesting patterns:
- The ratio of people in a county believing in climate change strongly correlates with counties’ median income
- The most significant predictors of belief in climate change include age, race, income, media exposure, and frequency of discussion about it
- Belief in climate change strongly correlates with belief in an obligation to mitigate its effects; same for disbelief and no obligation
Traditionally, social information has been taken as nothing but inputs to cognitive processes involved in belief formation. However, data like these show that the boundaries between social and cognitive processes aren’t always tidy, that there’s more to rational belief than internal cognitive processes and operating on socially-gathered information. There are at least two philosophically interesting points in these datasets. First, they pull philosophers away from idealizing believers and enables a finer-grained look at how believers actually live and engage the world. Second, they identify systematic consequences of culture on epistemic agents, offering a better understanding of how culture is relevant to belief-formation, contra mainstream analytic social epistemology.
The Self, the Book and the Community. Linguistic Identity Construction on Reading Platforms
Anna Mattfeldt (Bremen University)
23 November 2020, 14:00 on Zoom
Abstract
Reading platforms such as Lovelybooks or Goodreads offer readers a chance to evaluate the books they have read and write their own reviews. While this may at first resemble traditional forms such as a book review written by a journalist in the arts & leisure section of a newspaper, the linguistic practices of these lay online book reviews go far beyond simply evaluating a book. This paper shall show how the authors of book reviews establish their own identity in relation to the book in question when writing their posts, for example relating personal information, the reading situation including emotional responses or absorption, or other experiences unrelated to the book. By using a set of complex annotations, it can be shown how different aspects of identity may be combined in these reviews. Furthermore, the reactions by other readers who may comment on these reviews illustrate how these forms of self-positioning (Spitzmüller/Flubacher/Bendl 2017) are received by other participants in the same “affinity space” (Gee 2005) and which practices are seen as unmarked or marked behaviour within the community. Finally, it shall be discussed how the platforms differ from and resemble each other and how the choice of a platform and/or a language may influence the self-depiction.
References
Gee, James Paul (2005): Semiotic Social Spaces and Affinity Spaces. From The Age of Mythology to Today’s Schools. In: David Barton/Karin Tusting (eds.): Beyond communities of practice. Language, power and social context. New York: Cambridge University Press. 214-232.
Spitzmüller, Jürgen/Flubacher, Micha/Bendl, Christian (2017): Soziale Positionierung. Praxis und Praktik. In: Wiener Linguistische Gazette (WLG) 81, 1-18.
An Empirically Based Model of Literary Literacy. Valid for Reading on Paper and on Screen?
Chrsitel Meier (Friedrich-Alexander-University Erlangen-Nürnberg)
24 November 2020, 15:55 on Zoom
Abstract
An empirically based model of literary literacy. Valid for reading on paper and on screen? Empirical findings on whether the competencies of understanding literary and non-literary (expository) texts are different have been lacking for a long time. In a recent research project funded by the German Research Foundation (DFG) Meier et al. (2017) developed and tested a model of literary literacy indicating that comprehending literary texts encompasses additional competencies compared to the understanding of expository texts. The multifaceted competence model of literary literacy, which is based on the theory of aesthetic semiotics (Eco 1990), differentiates content-related and form-related aspects of comprehension, the recognition of foregrounded passages, the ability to apply specific literary knowledge, and the ability to recognize emotions intended by the text. Empirical studies conducted with 964 tenth grade students provide evidence for the validity of the model for reading on paper.
However, it is an open question if this competence structure also holds for reading literary and expository texts in digital environments. According to the meta-analysis by Delgado et al. (2018), understanding complex expository texts on screen is more difficult than reading on paper, whereas the comprehension of narrative texts does not seem to differ between print and digital reading. In contrast, Mangen et al. (2019) showed that readers performed better in a test on the chronology and temporality of narratives when the text was presented on paper as compared to a digital device (Kindle tablet). Overall, further research is needed to study whether and how changing the reading mode from print to digital devices affects the specific facets of literary literacy and its relation to expository reading comprehension. It is discussed how these questions can be investigated in a future research project.
References
Delgado, P., Vargas, C., Ackerman, R., and Salmerón, L. (2018). Don’t throw away your printed books: a meta-analysis on the effects of reading media on reading comprehension. Educ. Res. Rev. 25, 23–38. doi: 10.1016/j.edurev.2018.09.003
Eco, U. (1990). The limits of interpretation. Bloomington: Indiana University Press.
Mangen, A., Olivier, G. & Velay, J.-L. (2019). Comparing Comprehension of a Long Text Read in Print Book and on Kindle: Where in the Text and When in the Story? Front. Psychol. 10-38. doi: 10.3389/fpsyg.2019.00038.
Meier, C., Roick, T., Henschel, S., Brüggemann, J., Frederking, V., Rieder, A., Gerner, V. & Stanat, P. (2017). An extended model of literary literacy. In D. Leutner, J. Fleischer, J. Grünkorn & E. Klieme (Eds.): Competence Assessment in Education: Research, Models and Instruments. Cham: Springer International Publishing, 55-74.
Between Customers and Fans. Corpus Linguistic Perspectives on Writing Fan Reports as a Multifunctional Evaluation Practice.
Simon Meier-Vieracker (Bremen University)
23 November 2020, 16:00 on Zoom
Abstract
The German leading ticketing company eventim asks its online customers after the live event (mostly concerts) to give ratings and to write online reviews which are published as “fan reports” on the internet. As the live event visitors are framed as fans, the reviews fulfil thetwofold function of both rating the quality of the sold product as customers and self-presentation of their authors as fans and therefore as parts of a fan community. Based on a corpus of > 360.000 fan reports (approx. 28 mio. tokens), my talk will seek to explore corpus linguistic methods to approach the multifunctional nature of fan reports as online evaluation practices. By using the ratings as metadata (Meier 2019), I will ask for lexical and stylistic features of evaluative language (Hunston 2010). Moreover, I will focus on non-standard spellings which give the texts an oral and emotional character but also serve as a schibboleth in certain fan communities. I will argue that these features can be read as hints to the implicit standards of assessment that apply in the respective on- and offline communities (Arendt/Schäfer 2015). But still this interpretation needs to be counterbalanced by the intrinsic economic framework of the analysed evaluation practices. As I will show, corpus linguistic methods can serve as a complementary approach to more qualitative methods prevalent in the linguistic and sociological research on fans and fandom (Klemm 2012, Barton/Lampley 2014), by enabling researchers to work with much more data but also to trace the linguistic features of the fans’ admiration practices. In an outlook, some convergences and divergences with related rating practices in the field of social reading will be discussed.
References
Arendt, Birte/Schäfer, Pavla (2015): Bewertungen im Wissenschaftsdiskurs. Eine Analyse von Review-
Kommentaren als Aushandlungspraxis normativer Erwartungen. In: LiLi 177, S. 104–125.
Barton, Kristin M./Lampley, Jonathan Malcolm (2013): Fan CULTure: Essays on Participatory Fandom in the 21st Century. Jefferson: McFarland.
Klemm, Michael (2012): Doing being a fan im Web 2.0. Selbstdarstellung, soziale Stile und Aneignungspraktiken in Fanforen. In: Zeitschrift für angewandte Linguistik 56 (1), S. 3–32.
Hunston, Susan (2011): Corpus approaches to evaluation. Phraseology and evaluative language. London:
Routledge.
Meier, Simon (2019): Einzelkritiken in der Fußballberichterstattung. Evaluativer Sprachgebrauch aus
korpuspragmatischer Sicht. In: Muttersprache 129, S. 1–23.
How Lovely is Your Book? A Computational Study of Literary Evaluation on a German Social Reading Platform
Thomas Messerli, Simone Rebora & J. Berenike Hermann (University of Basel)
23 November 2020, 10:00 on Zoom
Abstract
The goal of our paper is twofold. On a more practical level, it examines the differences in behaviour of book reviewers across ratings and genres. On an epistemological level, it discusses and criticises the (computational) methods used to analyse such differences. The work is based on the LOBO corpus, comprising ~1.3 million book reviews in German language, downloaded from the social reading platform LovelyBooks.
Our methods of analysis fall into two main categories: wordcount-based sentiment analysis (SA) and advanced machine learning (ML). For the first category, a repository of six SA lexicons (sentiWS, NRC, ADU, LANG, Plutchik, and Ekman) was created. Lexicon formats were uniformed to automatically annotate reviews in a processing pipeline. For the second category, two ML approaches based on distributional representations of natural language (BERT and FastText) were trained on two manually-annotated datasets: in the first dataset (~21,000 sentences), the annotation task was that of identifying evaluative language (vs. descriptive language); in the second dataset (~6,000 sentences), the task focused on the distinction between positive and negative sentiment. Wordcount-based SA showed limitations in the extensiveness and coverage of lexicons (e.g., Plutchik has a hit rate of only 2.4% on the entire LOBO corpus), as well as in their reliability (detailed analysis of the German NRC lexicon identified ~28% of disputable emotion assignments). Advanced ML techniques depend primarily on the quality of the training material. However, the two annotators working on the LOBO corpus reached strong levels of agreement for both tasks (Cohen’s Kappa ~ 0.8), indicating their possible automation.
The annotated dataset offered also a ground truth for comparing the two methods: overall, ML proved substantially more efficient than SA. In a 5-fold cross validation (repeated five times to average variance), BERT reached a macro F1-score of .89 for the evaluative language task and of .85 for the positive vs. negative sentiment task (FastText’s scores were ~ .04 lower). Support vector machines trained on the features generated by the SA lexicons reached macro F1-scores of .62 and .58 for the two tasks. These computationally-generated annotations also offered the possibility to explore the LOBO corpus from a “distant reading” perspective. Here, SA methods provided more detailed results, e.g. mapping basic emotions to literary genres (see Figure 1). Such fine-grained visualizations were not possible with ML methods. However, they proved more efficient in distinguishing the ratings of the reviews (see Table 1).
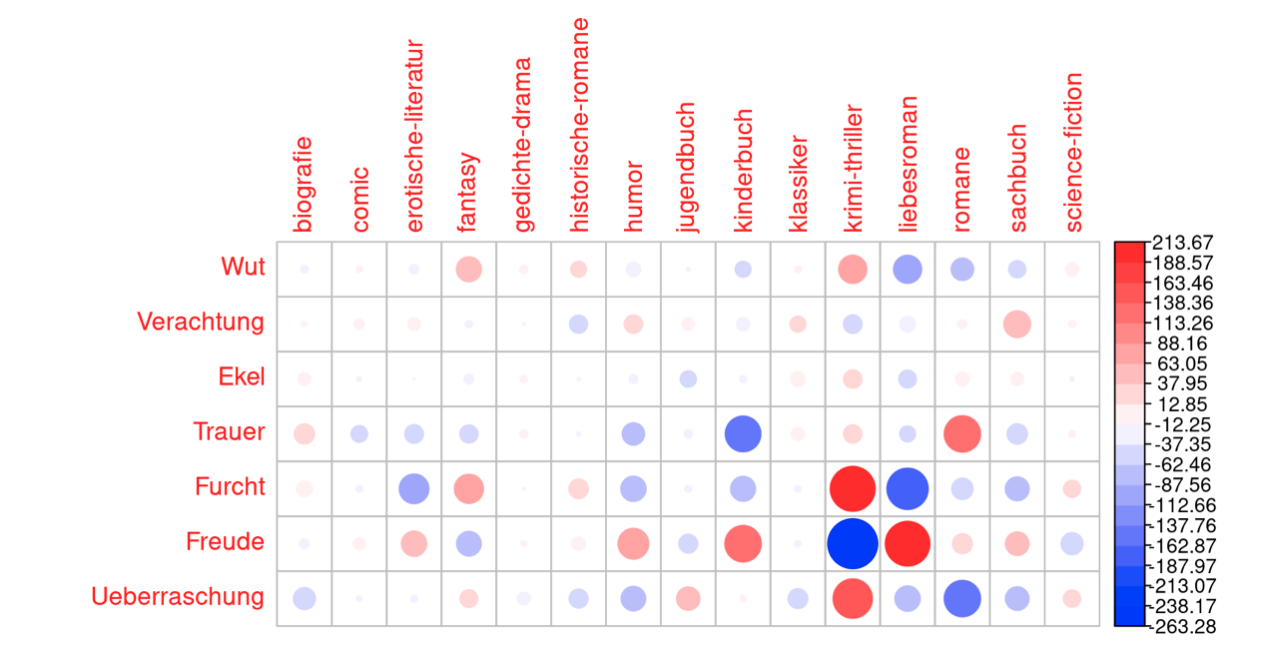
Figure 1. Chi-squared test residuals for Ekman’s seven basic emotions in the 16 LOBO genres.
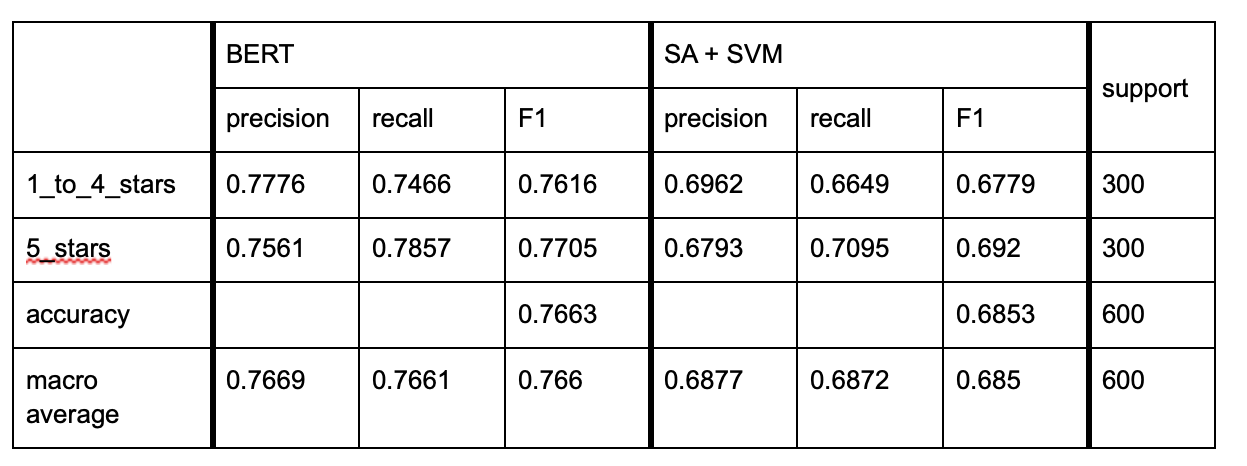
Table 1. Results of 5-fold cross validation for the rating prediction task.
Analyzing Online Reviews: Books vs. Museums. A Corpus Linguistic Approach
Anna Moskvina & Krisitna Petzold (University of Hildesheim)
23 November 2020, 13:30 on Zoom
Abstract
Digitization has significantly altered not only our perception of books but also changed the way we exchange our opinions about them. Multiple social reading platforms (Facebook), blogs, social media channels (Twitter) and trading platforms (Amazon) have become essential places for reviewing, reflection and evaluation of reading practices. The resulting generated data has become a promising research field to answer some of the following questions: What are the peculiarities associated with literary review processes in the digital sphere? How are they different from reviews in different fields?
Within the framework of our research we have collected extensive data from different literary review resources such as Amazon, büchertreff.de, and various blogs, but also reviews of museums, exhibitions and general discussion of cultural objects (Tripadvisor, blogs). Using traditional methods of corpus linguistics we analyzed the digital review processes in both datasets qualitatively and quantitatively.
In our paper we intend to show the differences between literary reviews and reviews of artwork or exhibitions that derive from variations in sentence length (short vs. long), syntactic patterns of sentences[1], length of reviews, preferred use of parts of speech[6], keywords [4],[5] and words from specific domains[2], social involvement of the interested community (taking into account the number of comments addressed to a given review). We identify differences between blogs for different themes (literary blogs vs. blogs about museums) and between different platforms (blogs vs. web forums[3]).
We could find evidence for the conclusion that the social context of the platform and the selfperception of the reader or reviewer play an important role for the way in which literary reviews are written and used as forms of productive reception and how they contribute to differences in writing style for specific platforms.
References
Bohnet, B. (2010). Top accuracy and fast dependency parsing is not a contradiction. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pages 89–97, Beijing, China, August. Coling 2010 Organizing Committee.
Hamp, B. and Feldweg H. (1997) Germanet – a lexical-semantic net for german. Automatic Information Extraction and Building of Lexical Semantic Resources for NLP Applications.
McAuley, J. and Leskovec, J. (2013). Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text. In Proceedings of the 7th ACM Conference on Recommender Systems, New York, USA: ACM
Rösiger, Ina, et al. (2016). Acquisition of semantic relations between terms: how far can we get with standard NLP tools?. In Proceedings of the 5th International Workshop on Computational Terminology (Computerm2016).
Schäfer, J., et al. (2015). Evaluating noise reduction strategies for terminology extraction Proceedings of the 11th International Conference on Terminology and Artificial Intelligence (TIA 2015), Granada, Spain, November.
Schmid, H. (1994) Probabilistic pos tagging using decision trees. In Proceedings of International Conference on New methods in Language Processing.
How Well Can Machines Understand Online Book Reviews?
Anna Moskvina & Rafael Rego Drumon(University of Hildesheim)
24 November 2020, 10:00 on Zoom
Abstract
Digital Humanities as a comparatively young discipline attracts methodologies and interests from different and previously rarely collaborating disciplines. Meanwhile, its various resources and the large amount of data made available via digitization allow the development of new research questions and interesting ideas.
Analysis of online book reviewing – one of the cornerstones of DH research – lies within the scope of the following paper. Unlike traditional literary critics, online review authors are free to decide on the structure and contents of their texts and the automatic analysis of review constituents gets extremely difficult. Following research by Kutzner et al., 2018 we applied a hierarchical annotation scheme based on components of reviews (their contents, the emotions of reviewers, their recommendations etc.) to a dataset extracted from the platform for book reviews büchertreff.de and to a subset of reviews published on Amazon till 2014. Then we trained two deep learning models: a Fully Convolutional Network (FCN) and a Very Deep Convolutional Neural Network (VDCNN) to extract the constituent blocks and we compared their performance.
The first set of experiments, based exclusively on the Amazon data, only concerned the 9 top level labels and our classifiers were able to achieve an F1-score of 0.8 for the category with most samples (2209).
In this paper we show our further experiments with both datasets (Amazon and Büchertreff), results on each layer of the hierarchical annotation labels, and a comparison of the results for the top, middle and bottom layers. The outcome of our models shows that the correlation between the number of samples for a label and the performance of the model does not always hold: thus the label showing the relation to other media (movies based on the book) with only 84 samples achieves F-score of 0.22±0.126 standard deviation and the label about the author of the book (biography, other works of the same author, etc.) with 128 samples got an F-score of 0.20±0.047 standard deviation.
References
McAuley, J. and Leskovec, J. (2013). Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text. In Proceedings of the 7th ACM Conference on Recommender Systems, New York, USA: ACM
Conneau, A., Schwenk, H., Barrault, L., and Lecun, Y. (2017). Very deep convolutional networks for text classification. Proceedings of the 15th Conference of the Euro- pean Chapter of the Association for Computational Lin- guistics: Volume 1, Long Papers.
Das, S. (1994). Time series analysis. Princeton University Press, Princeton, NJ.
Kaushal Paneri, V. T., Malhotra, P., Vig, L., and Shroff, G. (2019). Regularizing fully convolutional networks for time series classification by decorrelating filters.
Kutzner, K., Moskvina, A., Petzold, K., Roßkopf, C., Heid, U., and Knackstedt, R. (2018). Reviews of cultural arte- facts: Towards a schema for their annotation. August.
Wang, Z., Yan, W., and Oates, T. (2017). Time series clas- sification from scratch with deep neural
networks: A strong baseline. 2017 International Joint Conference on Neural Networks (IJCNN).
A Survey of Digital Reading Practices among Italian Wattpad Readers
Federico Pianzola (University of Milan-Bicocca)
23 November 2020, 16:30 on Zoom
Abstract
Data about teenagers’ reading activity and performance is being reported as alarming in many countries (OECD, 2019) , often blaming digital technology for shallow reading habits and literacy (Carr, 2014; Wolf, 2018) . However, many national and international surveys fail to record an important role played by digital media in reading practices: the success of digital social reading (Pianzola et al., 2020) . Here I present a survey conducted among Italian Wattpad readers, bringing evidence of how much teenagers read on this and other apps and website for digital social reading. Beside specific information about digital social reading, I collected data about the use of digital devices and social media, following the structure of the broad study conducted by Balling et al. (2019) . The results show intense reading habits
that are external to the traditional publishing industry: mobile reading is the most popular way of consuming fiction and the majority of the story read are published only online. In many cases, Wattpad is the first source of fiction for teenage readers, but paper books reading continues to be an important aspect for this kind of readership. My suggestion is that claims about the fate of reading in the age of
digitization should be reconsidered taking into account digital reading practices occurring on platforms like Wattpad, in order to provide more reliable data on the interest of teenagers for books.
References
Balling, G., Begnum, A. C., Kuzmičová, A., & Schilhab, T. (2019). The young read in new places, the older read on new devices: A survey of digital reading practices among librarians and Information Science students in Denmark. Participations, 16(1), 40.
Carr, N. G. (2014). The shallows: What the Internet is doing to our brains. Norton & Company.
OECD. (2019). PISA 2018 Results (Volume I): What Students Know and Can Do. OECD. https://doi.org/10.1787/5f07c754-en
Pianzola, F., Rebora, S., & Lauer, G. (2020). Wattpad as a resource for literary studies. Quantitative and qualitative examples of the importance of digital social reading and readers’ comments in the margins. PLoS ONE, 15(1), 46. https://doi.org/10.1371/journal. pone.0226708
Wolf, M. (2018). Reader, Come Home. The Reading Brain in a Digital World. Harper Collins.
Extracting Data from Baptismal Records through Coding
Amanda C.S. Pinheiro (Universidade de Brasília)
25 November 2020, 11:00 on Zoom
Abstract
This paper introduces a set of coding functions developed to capture data from the full transcription of baptism records from the eighteenth century. These functions were created to automatically extract all the names from social components within the records, such as parents’, godparents’, and grandparents names, in addition to information about the date, place and particular conditions (i.e. whether the newborn was abandoned, legitimate, etc.). The goal is to convert a set of approximately 9,500 records into a complete database. Full transcriptions are being utilised, mainly transcribed by researchers, but also produced by a particular HTR model from “Transkribus”(approximately 15%). The research started with a database (created in Filemaker Pro) with only 4 fields: the original record (the baptism text itself), I.D.(a unique identity code for every single record), book (to which the record belongs) and parish. Further, new fields were created in order to standardize the text, mainly names, surnames and abbreviations, with functions that convert linguistic variation into a standardised contemporary morphology (e.g. Manoel, Manuel). Frequently, the original textual structure follows an ordered pattern: a paragraph containing the date, church, newborn’s name, parents’ names, the grandparents (in some cases) and the godparents. Codes were subsequently created to automatically segment 3 sentences in which each type of data could be found, that pertaining to the date and church (Section A), the parents, baptized child and the grandparents (Section B), and the godparents’ (section C). This segmentation allows the system to find names based on their position in relation to their syntax field, which complements our coding. However, with numerous variations in data and textual style, our current aim is to identify a vast range of deviation and insert them within a coding system which permits the collection of more refined data.
Distant Reading Story World Absorption
Simone Rebora (University of Basel)
24 November 2020, 14:30 on Zoom
Abstract
The development of a tool for the automatic identification of absorption in millions of book reviews has a wide potential for literary studies, offering the opportunity to test theories, verify hypotheses, and propose new interpretations of still-understudied phenomena (Rebora, Lendvai, and Kuijpers 2018).
With this paper, I will present the possible use of the tools developed in the Mining Goodreads project (SNF project 10DL15_183194), with reference to the current discussion about literary modeling (Piper 2017) and to the most recent interpretations of the “distant reading” paradigm (Underwood 2017). Specifically, I will discuss limits and opportunities in the “operationalization” (Moretti 2013) of concepts like “worldbuilding” (Wolf 2013), “empathic identification” (Koopman and Hakemulder 2015) and “embodied simulation” (Gallese 2007) in the framework of the conceptually-consolidated and computationally-extended Story World Absorption Scale (Kuijpers et al. 2014).
Reasonings will be supported by analyses and visualizations on a larger and smaller scale: (1) applying the methods developed by Lendvai (2020) on a wide corpus of Fantasy, Romance, and Thriller book reviews; (2) working on a smaller, manually-annotated corpus.
References
Gallese, Vittorio. 2007. “Before and below ‘Theory of Mind’: Embodied Simulation and the Neural Correlates of Social Cognition.” Philosophical Transactions of the Royal Society B: Biological Sciences 362 (1480): 659–69. https://doi.org/10.1098/rstb.2006.2002.
Koopman, Eva Maria (Emy), and Frank Hakemulder. 2015. “Effects of Literature on Empathy and Self-Reflection: A Theoretical-Empirical Framework.” Journal of Literary Theory 9 (1). https://doi.org/10.1515/jlt-2015-0005.
Lendvai, Piroska. 2020. “Ranking of Social Reading Reviews Based on Richness in Narrative Absorption.” In Digital Practices. Reading, Writing and Evaluation on the Web.
Moretti, Franco. 2013. “‘Operationalizing’: Or, the Function of Measurement in Modern Literary Theory.” Pamphlet of the Stanford Literary Lab, 1–15.
Piper, Andrew. 2017. “Think Small: On Literary Modeling.” PMLA 132 (3): 651–58. https://doi.org/10.1632/pmla.2017.132.3.651.
Rebora, Simone, Piroska Lendvai, and Moniek Kuijpers. 2018. “Reader Experience Labeling Automatized: Text Similarity Classification of User-Generated Book Reviews.” In EADH2018. Galway: EADH. https://eadh2018.exordo.com/programme/presentation/90.
Underwood, Ted. 2017. “A Genealogy of Distant Reading.” DHQ: Digital Humanities Quarterly 11 (2).
Wolf, Mark J. P. 2013. Building Imaginary Worlds: The Theory and History of Subcreation. New York: Routledge.
The Stance Triangle in YouTube Comments: Evaluation, Positioning, and Alignment with Emojis
Anja Schmid-Stockmeyer (University of Basel)>
25 November 2020, 13:30 on Zoom
Abstract
With Unicode 12.0, a total of 3’019 different emojis are available to the creativity of the human mind, offering a multitude of possibilities to express oneself in computer-mediated communication (CMC). Even if each of them has a well-defined name, the meaning of an emoji is usage-based and can differ depending on the context (Dürscheid and Siever 2017: 268, Schneebeli 2017: 6f., Bich-Carrière 2019: 300f.). This paper is interested whether there are consistent and recurrent ways in which users use emojis to take stances in YouTube comments. It discusses questions of emoji-text relations, for example whether emojis are intensifiers or specifiers (Ochs and Schieffelin 1989) of the stance of the text which they accompany. Stance taking is conceptualized here according to the model of Du Bois’ (2007) stance triangle which states that every act of stance taking includes positioning, evaluation, and alignment. The paper then adopts a mixed methods approach in two steps in order to show how emojis can position a user, evaluate an object, and align with other stances on different levels of YouTube communication (Dynel 2014). A first quantitative analysis of a big dataset of YouTube comments compares the sentiment score of emojis (cf. Novak et al. 2015) to the sentiment score of the texts (cf. Warriner et al. 2013) in which they appear. Based on these findings, an emoji of interest is chosen – the ‘crying face’ – which is then analysed qualitatively. A conversational analytical approach (Goodwin and Heritage 1990) is complemented with concepts from small story research (Georgakopoulou 2013). The results show that there are recurrent ways, in which this emoji is used to take stances but that these ways are manifold. Thus, it can be assumed that emojis are pluridimensional tokens which cannot be organized on a simple scale from negative to positive. They express more than emotion. Such findings challenge and inspire qualitative as well as quantitative research on how to conceptualize and operationalize emojis as pictural units in the semantic framework of a CMC text.
Investigating the Transformation of Original Work by the Online Fan Fiction Community – A Case Study for Supernatural.
Thomas Schmidt & Nina Kleindienst (University of Regensburg)
23 November 2020, 15:30 on Zoom
Abstract
We want to present first results of a project investigating how online fan fiction communities use the original content and deviate from it in their fan fiction stories concerning language, characters/named entities, topics and sentiments. The analysis of this transformation process has led to multiple research in the humanities (cf. Van Steenhuyse, 2011) and we want to extend this work via methods of natural language processing and text mining. We examine the use case of the popular series “Supernatural” which is among the most popular TV shows for fan fictions. We acquired a structured corpus consisting of all the scripts and metadata of all Supernatural episodes marking speakers and speeches (as of today, the show consists of 14 season which equals to 307 episodes; see table 1).

To create the fanfiction corpus we scraped the popular fan fiction platform Archive of Our Own (AO3)1. For our first analysis we focused on the most popular Supernatural fan fictions (more than 300 kudos)
which resulted in 7,853 works (see table 2).

Among some of our first explorations, we analyze differences in the appearances and mentions of the main characters: Dean (Male), Sam (Male) and Castiel (Male) (the latter one being introduced in season 4). Table 3 summarizes some results.
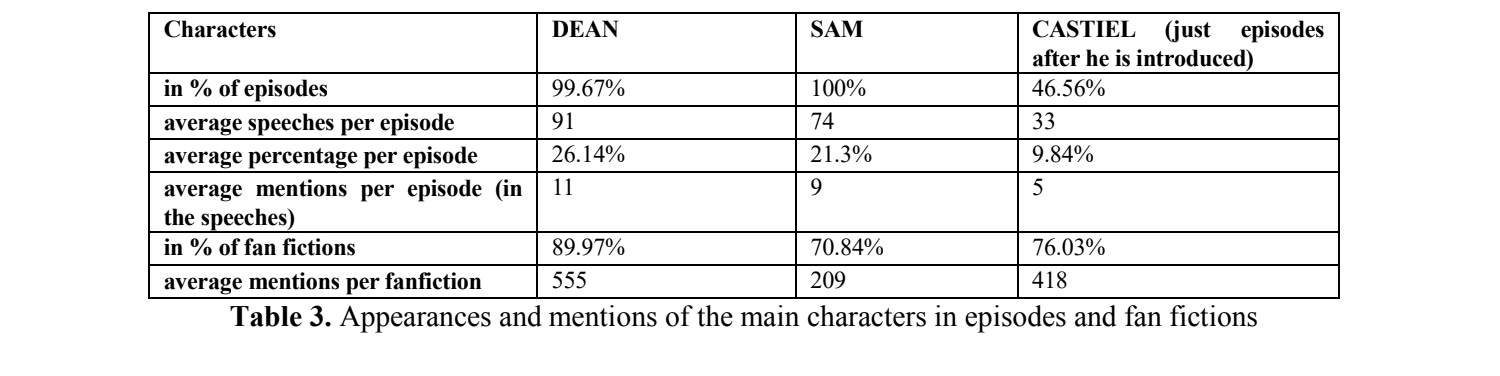
One can easily see how the character Castiel is overrepresented in the fan fictions compared to the original work being it appearances or mentions in the text. This is in line with general findings by Milli & Bamman (2016) concerning the overrepresentation of minor characters. More analysis about the metadata of fan fictions tagged with relationships show that the tag male/male makes up the majority of the corpus (90%) and furthermore the relationship of Castiel/Dean makes up 80% of those stories (see table 4).

This phenomenon concerning the dominance of homo-romantic content in fan fictions has been already identified in the humanities (cf. Hellekson & Busse, 2006; Tosenberger, 2008) and can be seen here via quantitative methods. Overall, the results also show how the online community influences the original work since the online popularity of Castiel lead to him becoming a major character in the show.
While our findings are currently limited on the use case of Supernatural, we are able to gain insights on how the fandom online community transforms the source material and differentiates from it via computational methods. We plan to further our analysis by applying sentiment analysis and topic modeling on our corpora. We would be happy to present these and more results as a poster, which also offers us the possibilities to discuss our plans and current problems.
References
Hellekson, K. & Busse, K. (2006). Fan Fiction and Fan Communities in the Age of the Internet: New Essays. Jefferson, NC: McFarland
Milli, S., & Bamman, D. (2016, November). Beyond canonical texts: A computational analysis of fan fiction. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 2048-2053).
Tosenberger, C. (2008). Homosexuality at the online Hogwarts: Harry Potter slash fan fiction. Children’s Literature, 36(1), 185-207.
Van Steenhuyse, V. (2011). The writing and reading of fan fiction and transformation theory. CLCWeb: Comparative Literature and Culture,
13(4), 4.
On the Connection of Social Media and the Question of Authorship
Nina Tolksdorf (Freie Universität Berlin)
25 November 2020, 14:30 on Zoom
Abstract
Hypertexts seemed to be the realization of poststructuralist theories of authorship. Collective and collaborative projects appeared to be the manifestation of Roland Barthes’ death of the author and the birth of the reader. Web 0.2 advances the position of the reader even further by allowing them to become an active part in collaborative narratives. The author as the creator and originator became obsolete, while digital practices of writing decentralized the very idea of the author and made concepts like the “wreader” (George Landow) possible. Contrary to the decentralized account of authorship, we can find a reverse tendency in contemporary literature: the call for authenticity of writers. Diverse literary genres constitute a perspective on authorship that is highly influenced by social media platforms. Instapoetry is one example that shows a strong interrelation between the display of the poet’s private life and the reception of their work. Another example is the hashtag ownvoice. It reflects upon the social and economic status of authors and makes the difficulties visible that go along with writing from unknown or unexperienced perspectives. The hashtag requests that authors should write from perspectives they can represent in an authentic way. Whereas the political implications of #ownvoice are an important step in the diversification of voices to be read, the call for authenticity can interfere with the very idea of the fictional. Considering that the German language feuilletons are generating a new genre by referring to texts like Min Kamp by Karl Ove Knausgård as “literary selfie”, the interrelatedness and influence of digital and social media with the construction of authorship becomes evident. Based on these contradictory accounts of authorship, the paper evaluates the interrelatedness of social media and the construction of authorship and discusses the difficulties and possibilities literary criticism faces as a consequence.
“What a Nice Picture!” Remediating Print-Based Reading Practices Through Bookstagram
Danai Tselenti (University of Basel)<
25 November 2020, 14:00 on Zoom
Abstract
Instagram, which is primarily a visual – smart-device-based – platform, has become one of the fastest growing social media networks, shaping progressively the online literary landscape. During the last few years, #bookstagram is becoming an ever-increasing trend, attracting substantial numbers of users. Bookstagram accounts are thematic in character and contain feeds focusing exclusively on book-related content, which ranges from book photography to book reviews, and even promotional posts. Despite the growing research interest in online reading communities, the body of work that explores the bookstagram phenomenon is notably scarce. In an attempt to fill this gap in the literature, this paper presents an ongoing study on 25 greek bookstagram public accounts identified through searches of popular book-related hashtags (#diavazo, #instavivlio, etc.) and followed during a period of one month. The research is conducted in the form of a qualitative content and thematic analysis and involves the detailed examination of visual content, captions, followers’ comments, use of hashtags, as well as post engagement. Preliminary results identify the different ways in which bookstagrammers stage the scenes of book reading as unique imageries, inscribable into an “aesthetic of bookishness” and blended with particular kinds of “design photo aesthetics”. Analysis shows how reader identities become entangled with bookish objects and indicates a variety of hashtag strategies for the formation of online bookish communities. It is claimed that bookstagram remediates print-based reading practices into new contexts of social visibility, whereby content interpretation is de-emphasized in favor of the visualization of the aesthetic experience of reading. In this respect, the paper highlights bookstagrammers as “aesthetic workers” and construes bookstagram as a particular genre of (post) digital “lectoral art” with distinctive online phenomenologies of the “bookish design-object” and as grounded in the enmeshment of the sensory and affective qualities of print-based reading with the affordances provided by the Instagram application.
References
Manovich, Lev. 2016. Instagram and Contemporary Image. Published online under
creative commons license. Available at: http://manovich.net/index.php/projects/instagram-and contemporary-image .
Pressman, Jessica. 2009. “The Aesthetic of Bookishness in Twenty-First-Century Literature.” Michigan Quarterly Review 48 (4): 465–482.
Stewart, Garrett. 2006. The Look of Reading: Book, Painting, Text. Chicago: University of Chicago Press.
Stewart, Garrett. 2011. Bookwork: Medium to Object to Concept to Art. Chicago; London: University of Chicago Press.
One in a Million? Solitary Reading and Social Networks
Marcus Willand (University of Heidelberg)
25 November 2020, 16:50 on Zoom
Abstract
In this paper we present a method for the analysis of entity associations that readers make in their reviews on goodreads.com. The results of our analyses are discussed with a view to the knowledge and contexts that users refer to while writing about a book online.
Theories of literary reception, of reading and of readers have been based on very different understandings of “reader” (cf. Willand 2014, 59-248). Most of them do not refer to real persons with books in their hands: professional readers (Dijkstra 1994), informed readers (Fish 1970, 86), model readers (Eco 1979) or even ideal readers (Schmid 2005) are theoretical instances of those approaches that – in the end – all have a hermeneutical background (Schleiermacher 1838, esp. 309f.; Iser 1976). A reason for neglecting the reception of real readers in literary studies is that empirical forms of reader/reading analyses are costly and time-consuming (questionnaires, interviews, peripheral physiology and eye-related measures, fMRI, etc).
This situation has changed fundamentally within the recent years. Since readers use social media to share their thoughts about the books they read, computer-supported empirical analyses of literary reviews open doors to innovative research in this field. Since computational “understanding” differs from human understanding, common questions and methods of reception studies had to be adapted. One of those questions is to ask about the function of literature for real readers and society (Gymnich et al., 2005) in the digital age. Our methodological approach to an answer is a corpus-based network analysis of the associations triggered by literary texts. In doing so, we limit ourselves to associations concerning living real or ‘living’ fictional entities, such as public figures (Donald Trump) or fictional characters (Harry Potter).